Exploratory Data Analysis - An Overview
An overview of the various steps taken into account during the EDA phase

Oracle Data/Application Consultant | Machine Learning Enthusiast | Data Scientist | Python Developer
Exploratory Data Analysis:
Today, I am going to explore in depth the first and most important phase of the machine-learning pipeline and that is Exploratory Data Analysis (EDA). EDA is the process of identifying and sorting out insights from the given dataset from an analytical point of view. This allows us to get a good grip on what our data represents, how well each field performs statistically and how many values need to be transformed for proficient results. Exploratory Data Analysis can be classified into different steps that take place one by one in the order illustrated in the figure. (This idea for classification is taken from the article Advanced exploratory data analysis (EDA) by Michael P. Notter)
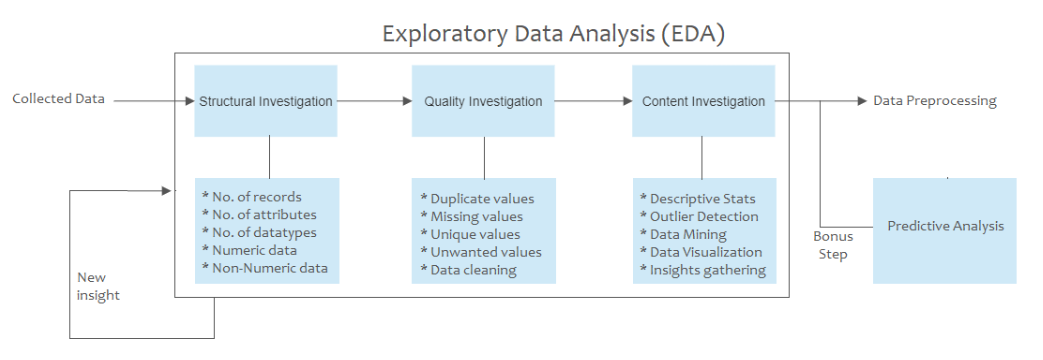
Let's cover each of these steps briefly:
1. Structural Investigation:
The first step of EDA deals with the structure of the data being analyzed. The structure of the data refers to the shape and data types of the tabular data. Structural Investigation can comprise different sub-steps such as
Computing Shape of Data: Finding the total number of records and fields in the provided data. This may later help us in identifying the purity of the dataset e.g. how much percentage of provided data was useful for making insights or useable for prediction purposes.
Investigating Attribute Datatypes: Finding the different datatypes carried by the attributes. This helps us in identifying the type of data we are dealing with i.e. how many varieties of the to-be-called features are in place and the ratio between the qualitative and quantitative variables provided in the given data.
Classification of Data Variables: One of the most crucial insights to get when analyzing the data is the kind of data represented by each attribute (Remember that by kind, I mean the kind of variable and not the datatype that is used to initialize it). After this step, one gains insights into how many numeric and non-numeric variables are present. Furthermore, which of the numeric attributes are nominal, ordinal, or continuous values? Similarly, we can classify the non-numeric variables into classes like DateTime, URLs, text passages, or some other type of object, etc., allowing us to get a good grip on what kind of preprocessing/analysis techniques are to be applied to each variable or combination of variables to get the most out of the result.
2. Quality Investigation:
The second step of EDA deals with the quality of the data being analyzed. The quality of the data refers to the different aspects from which the data is dirty in nature. Quality Investigation can comprise different sub-steps such as:
Finding Duplicate Values: Duplicate values are a very common problem found in many datasets. The duplicate values in later stages result in biases towards particular record(s). There are different ways in which you can deal with duplicate records e.g. dropping them off based on some subset, improvising the data source from which they occur, etc.
Finding Missing Values: Missing values are another common impurity found in most datasets. Since missing values mean nothing, they must be dealt with before performing any predictions. Missing values come in different types, giving different ways to deal with them e.g. dropping them off, imputing via statistical measures, etc.
Unique Values: Unique values provide insight into how many occurrences take place for a particular record or subset of a record. This helps in determining whether the dataset is imbalanced or which particular set of variables is the most common among different records. Datasets with too many or imbalanced proportions of unique values must be handled and taken care of using measures such as data permutation, data sampling or discretization, etc.
3. Content Investigation:
The third and last step of EDA deals with the content depicted by the stored data. By content, I mean the statistical significance each variable/record carries for the predictive analysis phase. Content Investigation can comprise different sub-steps such as:
Computing Descriptive Statistics: Descriptive statistics such as mean, median, variance, std, etc. are useful to analyze the distribution of the provided variables in the dataset. This helps us in finding out how much the values in a particular attribute scale, the trends they follow as well as their point of convergence. Descriptive stats are carried out as univariate analysis in the first stage.
Finding Outliers: Outliers are a very common occurrence and are removed with the help of statistical measures. The descriptive statistics provide a good approximation of which values might be outliers. Depending on the condition, outliers may be handled in different ways e.g. dropping records, using a trimmed statistical measure, clipping, etc.
Finding Correlation: An important part of exploratory data analysis is finding the relationship between the different variables (be it bi-variate or multi-variate). Correlation allows to give you an insight into which attributes are highly related to others. The correlated attributes are thus removed, which can help a lot in the later stages of the prediction process.
4. Bonus Stage: Prediction Analysis:
Sometimes there might be cases where we can give a certain prediction without heading toward the machine learning phase. Usually, such datasets are simpler in nature as statistical techniques are capable enough to provide insight for their relevant predictions. However, machine learning models are usually utilized to deal with this part as in many cases, computational hurdles are present which do not allow the user to manifest the prediction results using basic statistical techniques e.g. in use cases with a large dataset or with many features or with complex patterns hidden, etc.
Conclusion
So today, we overviewed the set of steps that take place when undergoing the EDA phase in the machine learning pipeline. As we can see EDA is a lengthy and insightful process as it establishes the foundation for the next set of steps in the machine learning cycle.
One thing to note before I finish is that although I have described which measures are taken to get rid of the different problems that are identified in these processes remember that we may or may not apply any of these measures in EDA based on how we are conducting the analysis. Usually, these measures take place in preprocessing step by putting the problem at hand under consideration. Finally, since the phase depends on one insight gathered from another, new insights might lead to reperforming the whole process to discover even newer insights.
That's it for today! Hope you enjoyed the article and got to learn something from it. Don't forget to comment with your feedback on the approach. How do you break your EDA phase when analyzing datasets? Do share the steps in the comments.
Thanks for reading! Hope you have a great day! 😄😄



