Overview of the Machine Learning Pipeline
A look into the fundamental steps in a machine learning pipeline...

Oracle Data/Application Consultant | Machine Learning Enthusiast | Data Scientist | Python Developer
Machine Learning is topping charts in terms of popularity nowadays, with the progress of AI-based art using generative image models, auto-transcribing of audios via speech-to-text systems, and general-purpose usage of LLMs to answer queries from large sets of passages, etc. With this trend in motion, one finds himself asking the question of what is machine learning. How is a machine able to predict what we are asking? How can it take a random image containing some text and extract it from it? How can it generate an image from only a brief description? Although the medium of technology differs for each of the tasks, the model that works behind the scenes is established on the same fundamental properties and processes of a machine learning model. In this article, I will go through the fundamental process of how a machine-learning model is created and trained to perform good predictions.
The Machine Learning Pipeline
The process of obtaining an efficient machine learning model comprises establishing a good and well-established machine learning pipeline. This pipeline comprises a set of steps, with each step ensuring a successful model. The pipeline is provided the input data and makes use of defined preprocessing and algorithms to generate a model as a result, which can then be used for prediction for data of the same distribution. The basic machine-learning pipeline process is illustrated in the figure.
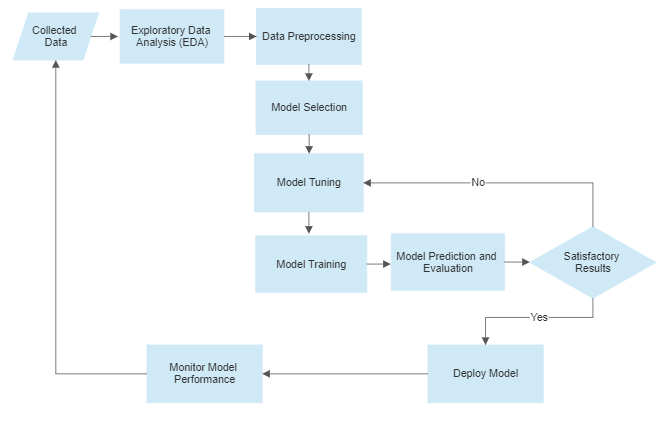
1. Data Collection
Data Collection is a prerequisite step taken before a machine-learning pipeline comes into practice. This collected data is obtained after proper extraction from different data resources via a data engineer and stored in some applicable file format, usually a CSV file, ready to be used for exploration and analysis by a Data Scientist.
2. Exploratory Data Analysis (EDA)
The process of Exploratory Data Analysis (EDA) is an essential step in the machine-learning process and is used to gather insights into the relationship between the different variables of data and their statistical nature. This includes finding descriptive measures, correlations, and other statistics about each attribute in the provided dataset. This step usually takes 80% of the time in the model development process as it is essential for the determination of the correct preprocessing and approach to use.
3. Data Preprocessing
Once the data has been properly analyzed, it undergoes the data preprocessing step. This step makes use of different techniques e.g. feature encoding, feature extraction, feature selection, etc. so as to obtain a ready-to-use format of data for the desired machine learning model. The set of techniques to use highly depends on the analysis conducted in the EDA step as well as the problem being targeted.
4. Model Selection
With the data in a proper format, the step of model selection takes place. This step makes use of the given problem statement and the nature of the data features, analyzed during the EDA phase, to obtain the right model. The selected model is then forwarded to the tuning stage.
5. Model Tuning
The obtained model is now tuned on the basis of different hyperparameters. The tuning process is usually iterative as it is based on trial and error by selecting different values for hyperparameters and then testing the results based on performance metrics. The selection of hyperparameters usually takes place based on some sort of cross-validation search technique that allows getting the optimal set of hyperparameters for a given sample.
6. Model Training
The tuned model is now trained on the processed data. Before training, the data is usually split into two halves i.e. training and testing sets with some sort of ratio as per requirement. The test set is kept for the evaluation phase later whereas the training set is divided into training and validation sets. The training process can take place based on different learning techniques as per the requirement. The training process also makes use of a set of metrics that are used to check the result of the trained model on the validation set before moving toward the evaluation phase.
7. Model Prediction and Evaluation
Once the model is trained and ready for use, the test set is passed to it, from which it is able to obtain predictions. The resulting predictions are tested with the actual targets via some metrics, depending on the type of problem being targeted. The final result of the metric is checked with the required threshold. If the results are satisfactory and as per the need, the model is sent to the deployment phase, otherwise, it is fine-tuned even more so as to obtain a better version of the model. In some cases, the model selection phase may take place instead of the tuning step.
8. Model Deployment
Model Deployment deals with the process of placing the trained model into the required live environment for usage purposes. The live environment may be some sort of API, special-purpose application's backend or cloud environment, etc. The deployed model then learns from and makes predictions on the live data provided to it in the production environment.
9. Model Monitoring
Once the model has been deployed, its performance is measured with the help of different performance metrics and dashboards. The new data keeps being supplied to the model via the data engineering process and performance is kept in check. If performance starts to drop or there turns out to be some change in the data process, a new cycle takes place so as to update the current model and maintain/upgrade the performance.
Conclusion:
So today, we covered the machine-learning pipeline process, an essential workflow that is required for the development of a successful machine-learning model. As we can see that the steps in the pipeline are dependent on each other, thus, increasing the efficiency of each step results in increasing the overall efficiency of the model as well. The pipeline is also a continuous process as it needs to be updated as per the live data being provided to it and needs to be regularly updated for new improvements.
That's it for today! Hope you enjoyed the article and got to learn something from it. Don't forget to comment with your feedback on the approach. Do you think this pipeline can be optimized even further? If so, do share your thoughts in the comments.
Thanks for reading! Hope you have a great day! 😄😄




